Edward Asiedu, MSc

Table of Contents
Introduction
As organisations grapple with cybersecurity landscapes that only appear to worsen, they are turning to large volumes of their own data for insights to protect themselves. Federating enterprise data to cloud storage solves the problem of containing the data, but gaining value from the data depends on the approach taken to federation. The previous article in this two-part series identified four vendor approaches to federating data, and their appealing elements. This article identifies some drawbacks of each federation approach, and steps to manage associated federation challenges. An understanding of the challenges helps enterprises to avoid unfulfilled expectations as they choose data federation approaches to underpin data analytics and risk management.
Close-Coupled Federation
[Centralised normalised data, localised for access]
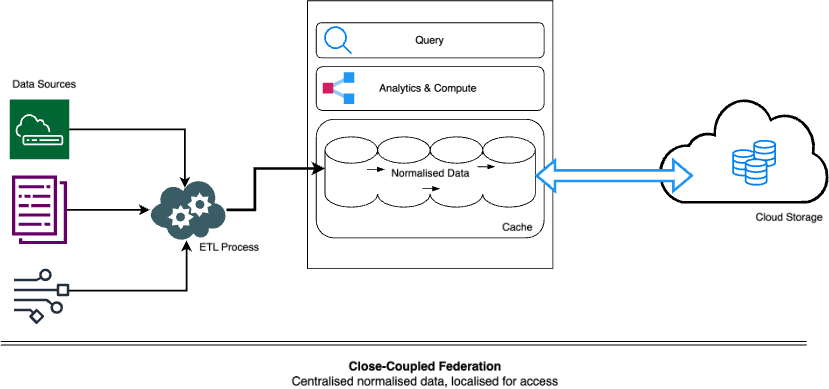
In this type of federation, we discussed the fact that elastic cloud storage becomes a de-coupled extension of the finite storage local storage, or cache.
However, the cloud storage introduces latency when the requirement is speed, so in this architecture, there are two mechanisms to keep data local even while federation is in use. Firstly, keeping recent and more frequently searched data in a local cache, while leaving space in the cache to retrieve older and less frequently searched data from its federated location. Secondly, moving out older and less frequently searched data from the cache to the federated location for retrieval if needed. With management logic governing the mechanisms, this approach can keep the benefits of local storage while leveraging federation.
Drawbacks
- In scenarios like threat hunting, if data that is older than a few months is frequently being searched, the size of the local data storage must be designed to be large from the start, to accommodate the large volumes that will be copied to local storage. This causes a corresponding increase in both local storage and compute, which reduces the cost-effectiveness of the architecture.
- In scenarios such as forensics, if a large amount of old data suddenly needs to be queried and correlated (say, three months of data from multiple sources) the close-coupled federation architecture may have storage contention issues. This is because the cache is typically sized to retain recent data and frequently queried data, say data from the current month to six months past. If, for instance, most data for months six to nine is being queried, a vicious cycle may arise where the cache allocated is constantly swapping data in and out of the federated storage. This is because a proportion of more recent data, whose location should be stable due to frequent querying, will be moved out to accommodate the older data for forensic queries, but then the older data will be removed when more recent data is queried. The cycle repeats, which can waste compute cycles and slow down analytics.
Managing Close-Coupled Federation
Considering the drawbacks, enterprises must:
- size the local storage well for their use-cases,
- use resource management tools in their federation to prevent queries whose time frame or expected result size will conflict with the allocated resource, and
- consider placing high-volume, low-signal data in other storage architectures. This advice has in fact been given by some close-coupled system vendors, along with product capabilities to do so.
Data-Fabric Federation
[Centralised matrixed data, accessed remotely]
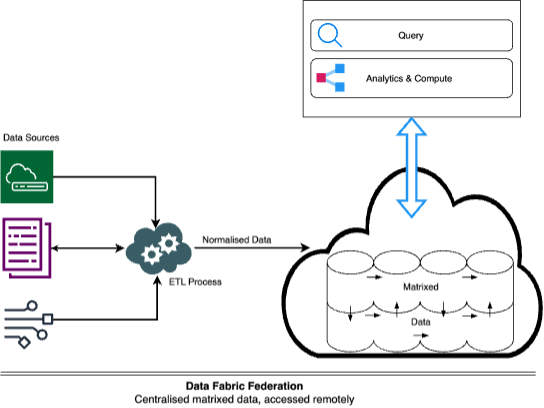
In this type of federation, we discussed how the architecture overcomes storage capacity limitations of close-coupled federations and provides domain and cross-domain normalisation.
Drawbacks
- Latency – the architecture is unable to query received data in true real-time, due to the separation between the data lake and the compute resource.
- While this architecture is intended to reduce repeated full-scale replication, data like asset information must be duplicated between it and a SIEM.
- Where inputs overlap with those into a close-coupled system, findings may be duplicated.
- From a TCO perspective, some additional compute costs may be generated inside the data lake.
Managing Data-Fabric Federation
Considering the drawbacks, enterprises must:
- Identify data sources for which sub-1-minute delays in querying are non-negotiable and continue to use a capable fast architecture (often close-coupled) for those situations
- To reduce costs, complement close-coupled systems with supplemental detections in a data-fabric federation that analyses high-volume security data efficiently
- Manage detections as code in a common repository and ensure detections are deployed only to one platform to avoid alert duplication
- Understand data lake cost regimes to avoid unanticipated costs
Inter-Platform Federation
[Remote multi-siloed data, fractionally normalised]
In this type of federation, we discussed how disparate enterprise repositories function as federated storage that is queried by a central layer, and where only the query results are normalised.
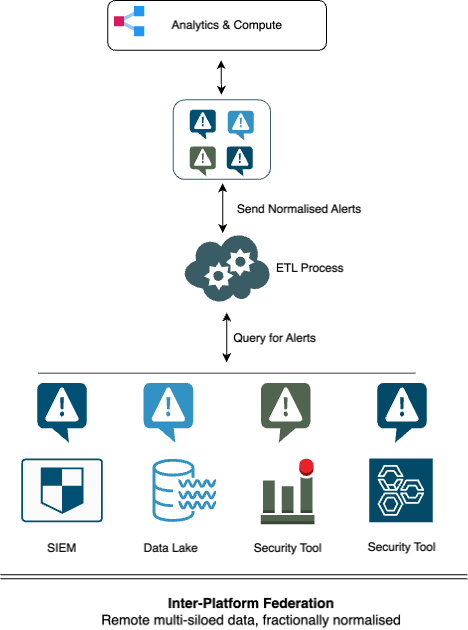
Drawbacks
- Though the central layer presents a unified place for queries, the data in the repositories remains siloed. This prevents any correlation before query results reach the central layer and often leads to atomic analytic results where each result never references data from another silo. This can cause a high proportion of false positives because at the time of query, contextual data from other repositories is not available to filter benign activity.
- The effectiveness of the central layer may be reduced because the central layer may inadvertently obstruct the visibility of issues in the data repositories. For example, security analysts get used to checking query results in the central layer and assume that a reduction in security detections means that there is a reduction in threat activity. However, there may be issues with analytics or the receipt of data at one of the data repositories, which might be a close-coupled system.
- The siloed architecture may not be oriented for answering a question that is framed as a storyline, such as: ‘Tell me about particular types of activity involving a device during a specific time frame’. Without raw data being centralised to tie seemingly disparate activities together, the activity may be missed by the siloed queries. For example, a successful brute force attack might be missed if there is no visibility of login attempts and outcomes across siloed authentication systems.
- Latency and inability to manage it across silos can prevent event correlation. For instance, if three repositories are queried for events that happened in the past hour, but one repository may receive data from sources three hours late (it happens), that incomplete information becomes the basis for decisions and responses.
Managing Inter-Platform Federation
Considering the drawbacks, enterprises must:
- Monitor the feed of data into their downstream repositories to be sure that any deviations in volume, latency or quality are addressed and do not reduce effectiveness at the central layer
- Ideally converge as many complementary data feeds into a single repository so that gaps are reduced when single-silo queries are made – for example, DNS, DHCP, Firewall, EDR and Proxy data are complimentary sources which could comprehensively answer questions about network activity even when these five data sources are alone in one repository
- Evaluate the suitability of this architecture for use-cases that routinely require wide-ranging correlation, such as insider threat monitoring
Reductive Federation
[Remote multi-siloed data, accessed in its default state]
We discussed how this type of federation shares much in common with Inter-Platform Federation – but to prevent unwanted surprises involving data integrity and availability, there is much more to manage. This is because data received by a destination can be destructively changed, with original security events losing their fidelity or dropped altogether.
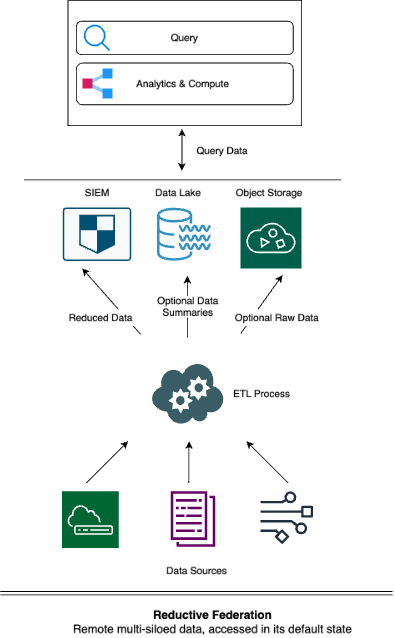
Such systems offer safety nets for this destruction, of course, being either of:
- offering the ability to replay the original events to the close-coupled system, like the previous destruction never happened, or
- copying original events to federated storage repositories, and then providing a central layer for querying such data while it remains in place at those federated locations. This typically requires learning a unified query language.
Drawbacks
Arising from its similarity to Inter-Platform Federation, Reductive Federation shares the previous four drawbacks, in addition to a couple more:
- Because it is often adopted as a workaround for close-coupled systems, a scenario such as a forensic investigation may arise where a decision is made to send replay data to the close-coupled system. It may however fail for either of two reasons:
- First, if the close-coupled system has a retention period (say 3 months) that is shorter than the age of replayed data (say 6 months), the data will be deleted upon receipt at the close-coupled system.
- Second, given the drive to reduce costs, the enterprise would almost certainly have reduced the local storage and/or ingestion capacity of its closed-coupled system. This means a sudden dump of forensic data would exceed that reduced capacity and cause the cache contention scenario described earlier. The result would be an under-capacity system that struggles to meet BAU while crawling to answer urgent forensic questions.
- Data would remain un-normalised without deliberate implementation activity, so datasets will be both siloed and misaligned for correlation.
Managing Reductive Federation
In addition to the management factors of Inter-Platform Federation, enterprises must:
- Evaluate what contingency they have prepared if they reduce the capacity of their close-coupled system
- Consider mitigations for any foreseeable scenarios in which they will require coherent and consistent correlation capabilities for large volumes of data
Conclusion
For enterprises drowning in data but starved for insights, data federation is emerging as a part of many ostensible solutions. This article provided an analysis of four federation approaches seen across different vendors, highlighted the respective advantages, and noted areas where management is required. Enterprises should tightly align their use-cases with solutions whose federation approach best meets their needs. The right choice of federated solution empowers enterprises to gain insights, defend themselves better, save money and minimise remedial management activity.
